小米澎程主创团队亮相 揭秘背后的核心力量
创始人2026-07-30 22:09:28
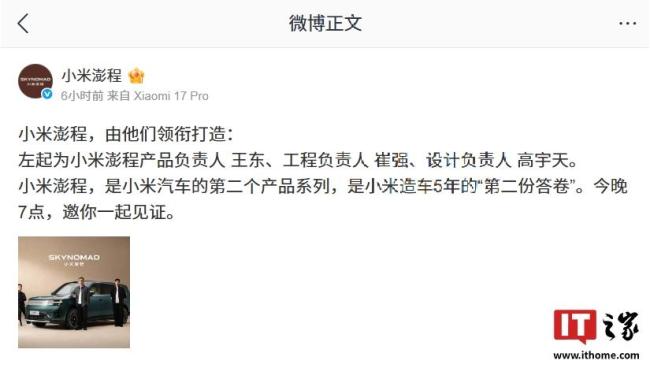
小米澎程官方今日公布了其主创团队成员,包括产品负责人王东、工程负责人崔强和设计负责人高宇天。小米澎程是小米汽车的第二个产品系列,标志着小米在造车领域的进一步探索
小米澎程官方今日公布了其主创团队成员,包括产品负责人王东、工程负责人崔强和设计负责人高宇天。小米澎程是小米汽车的第二个产品系列,标志着小米在造车领域的进一步探索。

据此前报道,小米将于今晚7点举行技术发布会,届时将介绍小米昆仑技术架构以及小米澎程N90 Max等新产品。发布会预计将持续2小时,但直播时间会更长。雷军将在会上详细介绍澎程系列,随后湖北、广东、四川和福建四地的工作人员会在直播间展示实车并讲解亮点。

所有文章未经授权禁止转载、摘编、复制或建立镜像,违规转载法律必究。
举报邮箱:1002263188@qq.com