美国为何下场救日元 防止局势失控
创始人2026-08-02 18:57:25
随着本周四、周五两天日元汇率跌至1986年以来的新低并多次出现异常波动,市场普遍预期日本政府将再次干预汇市。出乎意料的是,美国财政部也采取了行动。据知情人士透露,美国财政部在周五指示纽约联储执行“卖出欧元、买入日元”的操作
随着本周四、周五两天日元汇率跌至1986年以来的新低并多次出现异常波动,市场普遍预期日本政府将再次干预汇市。出乎意料的是,美国财政部也采取了行动。
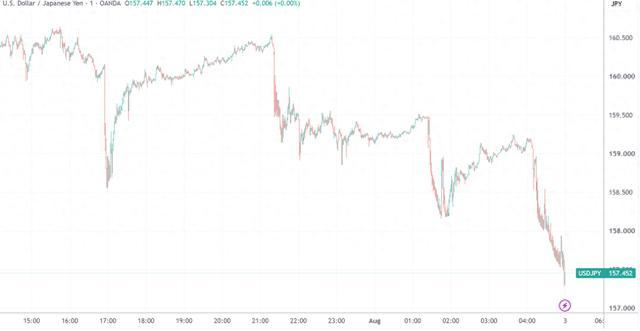
据知情人士透露,美国财政部在周五指示纽约联储执行“卖出欧元、买入日元”的操作。这一消息得到了美国财长贝森特的“小纸条”证实。在一次内阁会议上,贝森特在记事本上写下:“待办事项:买入日元(JPY),50-100亿。”这张纸条被记者拍下并在全球传播。

过去30年间,美国和日本联合干预汇市仅发生过两次。1998年亚洲金融危机期间,两国曾协同买入日元;2011年东日本大地震后,包括美国在内的西方7国与日本共同干预汇市以应对日元异常升值。

分析认为,贝森特此次亲自干预是为了防止日本局势失控影响美国国债。近期美伊战争及美联储新任主席沃什的信任危机导致美国长期国债收益率创下次贷危机以来的新高。如果日本此时抛售大量美债,将进一步加剧贝森特的压力。
所有文章未经授权禁止转载、摘编、复制或建立镜像,违规转载法律必究。
举报邮箱:1002263188@qq.com