国家医保局:前5个月基本医保参保人数达13.19亿 基金收入1.61万亿元
创始人2026-07-09 11:00:41
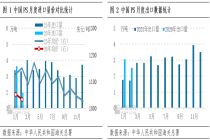
7月9日,在今日上午举行的2026年上半年例行新闻发布会上,国家医保局副主任王国栋介绍,今年1—5月,全国基本医保参保人数达13.19亿人,同比增加469万人。其中,职工医保参保3.86亿人,同比增加716万人;居民医保参保9.23亿人
7月9日,在今日上午举行的2026年上半年例行新闻发布会上,国家医保局副主任王国栋介绍,今年1—5月,全国基本医保参保人数达13.19亿人,同比增加469万人。其中,职工医保参保3.86亿人,同比增加716万人;居民医保参保9.23亿人,同比减少246万人,参保结构持续优化。同期,全国基本医保基金收入1.61万亿元,同比增长4.89%;基金支出1.21万亿元,同比增长2.12%。王国栋表示,今年上半年医疗保障制度运行总体平稳,参保规模保持稳定,医保基金运行总体平稳。
所有文章未经授权禁止转载、摘编、复制或建立镜像,违规转载法律必究。
举报邮箱:1002263188@qq.com